MAC下显示系统隐藏目录和文件
终端输入:
sudo chflangs nohidden [文件名或目录名]
要恢复隐藏属性:
sudo chflags hidden [文件名或目录名]
MAC下显示系统隐藏目录和文件
终端输入:
sudo chflangs nohidden [文件名或目录名]
要恢复隐藏属性:
sudo chflags hidden [文件名或目录名]
这是因post-commit脚本文件的权限不对,post-commit 脚本必须有 +x 权限
chmod +x post-commit
2. web service中调用svn update失败的问题
执行 shell 指令前要加上 export LANG=C.UTF-8 的环境声明,不然 SVN update 时遇到中文会出现 error,Ubuntu 的 Apache 默认是 LANG=C
比如PHP脚本中需要添加如下代码:
putenv(‘LC_CTYPE=zh_CN.UTF-8’);
putenv(‘LANG=zh_CN.UTF-8’);
2011.1.21 微信正式发布。这一天距离微信项目启动日约为2个月。就在这2个月里,微信从无到有,大家可能会好奇这期间微信后台做的最重要的事情是什么?
我想应该是以下三件事:
微信起初定位是一个通讯工具,作为通讯工具最核心的功能是收发消息。微信团队源于广硏团队,消息模型跟邮箱的邮件模型也很有渊源,都是存储转发。

图 1 微信消息模型
图1展示了这一消息模型,消息被发出后,会先在后台临时存储;为使接收者能更快接收到消息,会推送消息通知给接收者;最后客户端主动到服务器收取消息。
由于用户的帐户、联系人和消息等数据都在服务器存储,如何将数据同步到客户端就成了很关键的问题。为简化协议,我们决定通过一个统一的数据同步协议来同步用户所有的基础数据。
最初的方案是客户端记录一个本地数据的快照(Snapshot),需要同步数据时,将Snapshot带到服务器,服务器通过计算Snapshot与服务器数据的差异,将差异数据发给客户端,客户端再保存差异数据完成同步。不过这个方案有两个问题:一是Snapshot会随着客户端数据的增多变得越来越大,同步时流量开销大;二是客户端每次同步都要计算Snapshot,会带来额外的性能开销和实现复杂度。
几经讨论后,方案改为由服务计算Snapshot,在客户端同步数据时跟随数据一起下发给客户端,客户端无需理解Snapshot,只需存储起来,在下次数据同步数据时带上即可。同时,Snapshot被设计得非常精简,是若干个Key-Value的组合,Key代表数据的类型,Value代表给到客户端的数据的最新版本号。Key有三个,分别代表:帐户数据、联系人和消息。这个同步协议的一个额外好处是客户端同步完数据后,不需要额外的ACK协议来确认数据收取成功,同样可以保证不会丢数据:只要客户端拿最新的Snapshot到服务器做数据同步,服务器即可确认上次数据已经成功同步完成,可以执行后续操作,例如清除暂存在服务的消息等等。
此后,精简方案、减少流量开销、尽量由服务器完成较复杂的业务逻辑、降低客户端实现的复杂度就作为重要的指导原则,持续影响着后续的微信设计开发。记得有个比较经典的案例是:我们在微信1.2版实现了群聊功能,但为了保证新旧版客户端间的群聊体验,我们通过服务器适配,让1.0版客户端也能参与群聊。
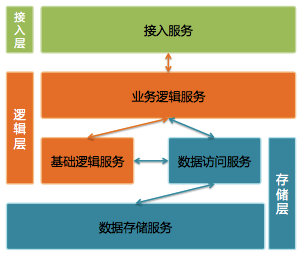
图 2 微信后台系统架构
微信后台使用三层架构:接入层、逻辑层和存储层。
微信后台主要使用C++。后台服务使用Svrkit框架搭建,服务之间通过同步RPC进行通讯。
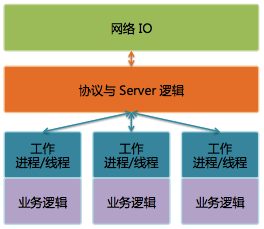
图 3 Svrkit 框架
Svrkit是另一个广硏后台就已经存在的高性能RPC框架,当时尚未广泛使用,但在微信后台却大放异彩。作为微信后台基础设施中最重要的一部分,Svrkit这几年一直不断在进化。我们使用Svrkit构建了数以千计的服务模块,提供数万个服务接口,每天RPC调用次数达几十万亿次。
这三件事影响深远,乃至于5年后的今天,我们仍继续沿用最初的架构和协议,甚至还可以支持当初1.0版的微信客户端。
这里有一个经验教训——运营支撑系统真的很重要。第一个版本的微信后台是仓促完成的,当时只是完成了基础业务功能,并没有配套的业务数据统计等等。我们在开放注册后,一时间竟没有业务监控页面和数据曲线可以看,注册用户数是临时从数据库统计的,在线数是从日志里提取出来的,这些数据通过每个小时运行一次的脚本(这个脚本也是当天临时加的)统计出来,然后自动发邮件到邮件组。还有其他各种业务数据也通过邮件进行发布,可以说邮件是微信初期最重要的数据门户。
2011.1.21 当天最高并发在线数是 491,而今天这个数字是4亿。
在微信发布后的4个多月里,我们经历了发布后火爆注册的惊喜,也经历了随后一直不温不火的困惑。
这一时期,微信做了很多旨在增加用户好友量,让用户聊得起来的功能。打通腾讯微博私信、群聊、工作邮箱、QQ/邮箱好友推荐等等。对于后台而言,比较重要的变化就是这些功能催生了对异步队列的需求。例如,微博私信需要跟外部门对接,不同系统间的处理耗时和速度不一样,可以通过队列进行缓冲;群聊是耗时操作,消息发到群后,可以通过异步队列来异步完成消息的扩散写等等。
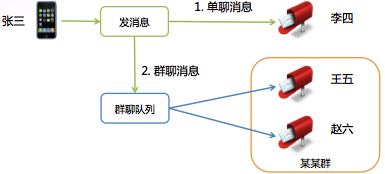
图 4 单聊和群聊消息发送过程
图4是异步队列在群聊中的应用。微信的群聊是写扩散的,也就是说发到群里的一条消息会给群里的每个人都存一份(消息索引)。为什么不是读扩散呢?有两个原因:
异步队列作为后台数据交互的一种重要模式,成为了同步RPC服务调用之外的有力补充,在微信后台被大量使用。
微信的飞速发展是从2.0版开始的,这个版本发布了语音聊天功能。之后微信用户量急速增长,2011.5用户量破100万、2011.7 用户量破1000万、2012.3 注册用户数突破1亿。
伴随着喜人成绩而来的,还有一堆幸福的烦恼。
帮助我们顺利度过这个阶段的,是以下几个举措:
虽然各种需求扑面而来,但我们每个实现方案都是一丝不苟完成的。实现需求最大的困难不是设计出一个方案并实现出来,而是需要在若干个可能的方案中,甄选出最简单实用的那个。
这中间往往需要经过几轮思考——讨论——推翻的迭代过程,谋定而后动有不少好处,一方面可以避免做出华而不实的过度设计,提升效率;另一方面,通过详尽的讨论出来的看似简单的方案,细节考究,往往是可靠性最好的方案。
逻辑层的业务逻辑服务最早只有一个服务模块(我们称之为mmweb),囊括了所有提供给客户端访问的API,甚至还有一个完整的微信官网。这个模块架构类似Apache,由一个CGI容器(CGIHost)和若干CGI组成(每个CGI即为一个API),不同之处在于每个CGI都是一个动态库so,由CGIHost动态加载。
在mmweb的CGI数量相对较少的时候,这个模块的架构完全能满足要求,但当功能迭代加快,CGI量不断增多之后,开始出现问题:
1) 每个CGI都是动态库,在某些CGI的共用逻辑的接口定义发生变化时,不同时期更新上线的CGI可能使用了不同版本的逻辑接口定义,会导致在运行时出现诡异结果或者进程crash,而且非常难以定位;
2) 所有CGI放在一起,每次大版本发布上线,从测试到灰度再到全面部署完毕,都是一个很漫长的过程,几乎所有后台开发人员都会被同时卡在这个环节,非常影响效率;
3) 新增的不太重要的CGI有时稳定性不好,某些异常分支下会crash,导致CGIHost进程无法服务,发消息这些重要CGI受影响没法运行。
于是我们开始尝试使用一种新的CGI架构——Logicsvr。
Logicsvr基于Svrkit框架。将Svrkit框架和CGI逻辑通过静态编译生成可直接使用HTTP访问的Logicsvr。我们将mmweb模块拆分为8个不同服务模块。拆分原则是:实现不同业务功能的CGI被拆到不同Logicsvr,同一功能但是重要程度不一样的也进行拆分。例如,作为核心功能的消息收发逻辑,就被拆为3个服务模块:消息同步、发文本和语音消息、发图片和视频消息。
每个Logicsvr都是一个独立的二进制程序,可以分开部署、独立上线。时至今日,微信后台有数十个Logicsvr,提供了数百个CGI服务,部署在数千台服务器上,每日客户端访问量几千亿次。
除了API服务外,其他后台服务模块也遵循“大系统小做”这一实践准则,微信后台服务模块数从微信发布时的约10个模块,迅速上涨到数百个模块。
这一时期,后台故障很多。比故障更麻烦的是,因为监控的缺失,经常有些故障我们没法第一时间发现,造成故障影响面被放大。
监控的缺失一方面是因为在快速迭代过程中,重视功能开发,轻视了业务监控的重要性,有故障一直是兵来将挡水来土掩;另一方面是基础设施对业务逻辑监控的支持度较弱。基础设施提供了机器资源监控和Svrkit服务运行状态的监控。这个是每台机器、每个服务标配的,无需额外开发,但是业务逻辑的监控就要麻烦得多了。当时的业务逻辑监控是通过业务逻辑统计功能来做的,实现一个监控需要4步:
1) 申请日志上报资源;
2) 在业务逻辑中加入日志上报点,日志会被每台机器上的agent收集并上传到统计中心;
3) 开发统计代码;
4) 实现统计监控页面。
可以想象,这种费时费力的模式会反过来降低开发人员对加入业务监控的积极性。于是有一天,我们去公司内的标杆——即通后台(QQ后台)取经了,发现解决方案出乎意料地简单且强大:
1) 故障报告
之前每次故障后,是由QA牵头出一份故障报告,着重点是对故障影响的评估和故障定级。新的做法是每个故障不分大小,开发人员需要彻底复盘故障过程,然后商定解决方案,补充出一份详细的技术报告。这份报告侧重于:如何避免同类型故障再次发生、提高故障主动发现能力、缩短故障响应和处理过程。
2) 基于 ID-Value 的业务无关的监控告警体系
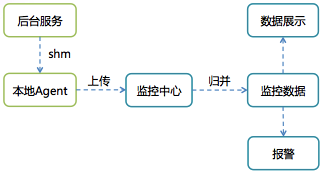
图 5 基于 ID-Value 的监控告警体系
监控体系实现思路非常简单,提供了2个API,允许业务代码在共享内存中对某个监控ID进行设置Value或累加Value的功能。每台机器上的Agent会定时将所有ID-Value上报到监控中心,监控中心对数据汇总入库后就可以通过统一的监控页面输出监控曲线,并通过预先配置的监控规则产生报警。
对于业务代码来说,只需在要被监控的业务流程中调用一下监控API,并配置好告警条件即可。这就极大地降低了开发监控报警的成本,我们补全了各种监控项,让我们能主动及时地发现问题。新开发的功能也会预先加入相关监控项,以便在少量灰度阶段就能直接通过监控曲线了解业务是否符合预期。
微信后台每个存储服务都有自己独立的存储模块,是相互独立的。每个存储服务都有一个业务访问模块和一个底层存储模块组成。业务访问层隔离业务逻辑层和底层存储,提供基于RPC的数据访问接口;底层存储有两类:SDB和MySQL。
SDB适用于以用户UIN(uint32_t)为Key的数据存储,比方说消息索引和联系人。优点是性能高,在可靠性上,提供基于异步流水同步的Master-Slave模式,Master故障时,Slave可以提供读数据服务,无法写入新数据。
由于微信账号为字母+数字组合,无法直接作为SDB的Key,所以微信帐号数据并非使用SDB,而是用MySQL存储的。MySQL也使用基于异步流水复制的Master-Slave模式。
第1版的帐号存储服务使用Master-Slave各1台。Master提供读写功能,Slave不提供服务,仅用于备份。当Master有故障时,人工切读服务到Slave,无法提供写服务。为提升访问效率,我们还在业务访问模块中加入了memcached提供Cache服务,减少对底层存储访问。
第2版的帐号存储服务还是Master-Slave各1台,区别是Slave可以提供读服务,但有可能读到脏数据,因此对一致性要求高的业务逻辑,例如注册和登录逻辑只允许访问Master。当Master有故障时,同样只能提供读服务,无法提供写服务。
第3版的帐号存储服务采用1个Master和多个Slave,解决了读服务的水平扩展能力。
第4版的帐号服务底层存储采用多个Master-Slave组,每组由1个Master和多个Slave组成,解决了写服务能力不足时的水平扩展能力。
最后还有个未解决的问题:单个Master-Slave分组中,Master还是单点,无法提供实时的写容灾,也就意味着无法消除单点故障。另外Master-Slave的流水同步延时对读服务有很大影响,流水出现较大延时会导致业务故障。于是我们寻求一个可以提供高性能、具备读写水平扩展、没有单点故障、可同时具备读写容灾能力、能提供强一致性保证的底层存储解决方案,最终KVSvr应运而生。
KVSvr使用基于Quorum的分布式数据强一致性算法,提供Key-Value/Key-Table模型的存储服务。传统Quorum算法的性能不高,KVSvr创造性地将数据的版本和数据本身做了区分,将Quorum算法应用到数据的版本的协商,再通过基于流水同步的异步数据复制提供了数据强一致性保证和极高的数据写入性能,另外KVSvr天然具备数据的Cache能力,可以提供高效的读取性能。
KVSvr一举解决了我们当时迫切需要的无单点故障的容灾能力。除了第5版的帐号服务外,很快所有SDB底层存储模块和大部分MySQL底层存储模块都切换到KVSvr。随着业务的发展,KVSvr也不断在进化着,还配合业务需要衍生出了各种定制版本。现在的KVSvr仍然作为核心存储,发挥着举足轻重的作用。
2011.8 深圳举行大运会。微信推出“微信深圳大运志愿者服务中心”服务号,微信用户可以搜索“szdy”将这个服务号加为好友,获取大会相关的资讯。当时后台对“szdy”做了特殊处理,用户搜索时,会随机返回“szdy01”,“szdy02”,…,“szdy10”这10个微信号中的1个,每个微信号背后都有一个志愿者在服务。
2011.9 “微成都”落户微信平台,微信用户可以搜索“wechengdu”加好友,成都市民还可以在“附近的人”看到这个号,我们在后台给这个帐号做了一些特殊逻辑,可以支持后台自动回复用户发的消息。
这种需求越来越多,我们就开始做一个媒体平台,这个平台后来从微信后台分出,演变成了微信公众平台,独立发展壮大,开始了微信的平台化之路。除微信公众平台外,微信后台的外围还陆续出现了微信支付平台、硬件平台等等一系列平台。
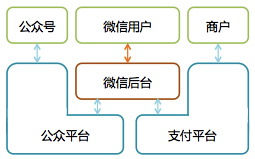
图 6 微信平台
微信走出国门的尝试开始于3.0版本。从这个版本开始,微信逐步支持繁体、英文等多种语言文字。不过,真正标志性的事情是第一个海外数据中心的投入使用。
海外数据中心的定位是一个自治的系统,也就是说具备完整的功能,能够不依赖于国内数据中心独立运作。
1) 多数据中心架构
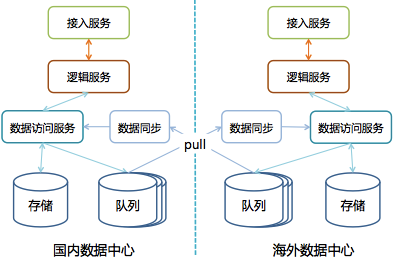
图 7 多数据中心架构
系统自治对于无状态的接入层和逻辑层来说很简单,所有服务模块在海外数据中心部署一套就行了。
但是存储层就有很大麻烦了——我们需要确保国内数据中心和海外数据中心能独立运作,但不是两套隔离的系统各自部署,各玩各的,而是一套业务功能可以完全互通的系统。因此我们的任务是需要保证两个数据中心的数据一致性,另外Master-Master架构是个必选项,也即两个数据中心都需要可写。
2) Master-Master 存储架构
Master-Master架构下数据的一致性是个很大的问题。两个数据中心之间是个高延时的网络,意味着在数据中心之间直接使用Paxos算法、或直接部署基于Quorum的KVSvr等看似一劳永逸的方案不适用。
最终我们选择了跟Yahoo!的PNUTS系统类似的解决方案,需要对用户集合进行切分,国内用户以国内上海数据中心为Master,所有数据写操作必须回到国内数据中心完成;海外用户以海外数据中心为Master,写操作只能在海外数据中心进行。从整体存储上看,这是一个Master-Master的架构,但细到一个具体用户的数据,则是Master-Slave模式,每条数据只能在用户归属的数据中心可写,再异步复制到其他数据中心。
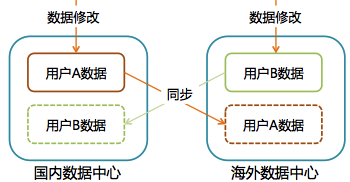
图 8 多数据中心的数据Master-Master架构
3) 数据中心间的数据一致性
这个Master-Master架构可以在不同数据中心间实现数据最终一致性。如何保证业务逻辑在这种数据弱一致性保证下不会出现问题?
这个问题可以被分解为2个子问题:
4) 可靠的数据同步
数据中心之间有大量的数据同步,数据是否能够达到最终一致,取决于数据同步是否可靠。为保证数据同步的可靠性,提升同步的可用性,我们又开发一个基于Quorum算法的队列组件,这个组件的每一组由3机存储服务组成。与一般队列的不同之处在于,这个组件对队列写入操作进行了大幅简化,3机存储服务不需要相互通讯,每个机器上的数据都是顺序写,执行写操作时在3机能写入成功2份即为写入成功;若失败,则换另外一组再试。因此这个队列可以达到极高的可用性和写入性能。每个数据中心将需要同步的数据写入本数据中心的同步队列后,由其他数据中心的数据重放服务将数据拉走并进行重放,达到数据同步的目的。
海外数据中心建设周期长,投入大,微信只在香港和加拿大有两个海外数据中心。但世界那么大,即便是这两个数据中心,也还是没法辐射全球,让各个角落的用户都能享受到畅快的服务体验。
通过在海外实际对比测试发现,微信客户端在发消息等一些主要使用场景与主要竞品有不小的差距。为此,我们跟公司的架构平台部、网络平台部和国际业务部等兄弟部门一起合作,围绕海外数据中心,在世界各地精心选址建设了数十个POP点(包括信令加速点和图片CDN网络)。另外,通过对移动网络的深入分析和研究,我们还对微信的通讯协议做了大幅优化。微信最终在对比测试中赶上并超过了主要的竞品。
2013.7.22 微信发生了有史以来最大规模的故障,消息收发和朋友圈等服务出现长达5个小时的故障,故障期间消息量跌了一半。故障的起因是上海数据中心一个园区的主光纤被挖断,近2千台服务器不可用,引发整个上海数据中心(当时国内只有这一个数据中心)的服务瘫痪。
故障时,我们曾尝试把接入到故障园区的用户切走,但收效甚微。虽然数百个在线模块都做了容灾和冗余设计,单个服务模块看起来没有单点故障问题;但整体上看,无数个服务实例散布在数据中心各个机房的8千多台服务器内,各服务RPC调用复杂,呈网状结构,再加上缺乏系统级的规划和容灾验证,最终导致故障无法主动恢复。在此之前,我们知道单个服务出现单机故障不影响系统,但没人知道2千台服务器同时不可用时,整个系统会出现什么不可控的状况。
其实在这个故障发生之前3个月,我们已经在着手解决这个问题。当时上海数据中心内网交换机异常,导致微信出现一个出乎意料的故障,在13分钟的时间里,微信消息收发几乎完全不可用。在对故障进行分析时,我们发现一个消息系统里一个核心模块三个互备的服务实例都部署在同一机房。该机房的交换机故障导致这个服务整体不可用,进而消息跌零。这个服务模块是最早期(那个时候微信后台规模小,大部分后台服务都部署在一个数据园区里)的核心模块,服务基于3机冗余设计,年复一年可靠地运行着,以至于大家都完全忽视了这个问题。
为解决类似问题,三园区容灾应运而生,目标是将上海数据中心的服务均匀部署到3个物理上隔离的数据园区,在任意单一园区整体故障时,微信仍能提供无损服务。
1) 同时服务
传统的数据中心级灾备方案是“两地三中心”,即同城有两个互备的数据中心,异地再建设一个灾备中心,这三个数据中心平时很可能只有一个在提供在线服务,故障时再将业务流量切换到其他数据中心。这里的主要问题是灾备数据中心无实际业务流量,在主数据中心故障时未必能正常切换到灾备中心,并且在平时大量的备份资源不提供服务,也会造成大量的资源浪费。
三园区容灾的核心是三个数据园区同时提供服务,因此即便某个园区整体故障,那另外两个园区的业务流量也只会各增加50%。反过来说,只需让每个园区的服务器资源跑在容量上限的2/3,保留1/3的容量即可提供无损的容灾能力,而传统“两地三中心”则有多得多的服务器资源被闲置。此外,在平时三个园区同时对外服务,因此我们在故障时,需要解决的问题是“怎样把业务流量切到其他数据园区?”,而不是“能不能把业务流量切到其他数据园区?”,前者显然是更容易解决的一个问题。
2) 数据强一致
三园区容灾的关键是存储模块需要把数据均匀分布在3个数据园区,同一份数据要在不同园区有2个以上的一致的副本,这样才能保证任意单一园区出灾后,可以不中断地提供无损服务。由于后台大部分存储模块都使用KVSvr,这样解决方案也相对简单高效——将KVSvr的每1组机器都均匀部署在3个园区里。
3) 故障时自动切换
三园区容灾的另一个难点是对故障服务的自动屏蔽和自动切换。即要让业务逻辑服务模块能准确识别出某些下游服务实例已经无法访问,然后迅速自动切到其他服务实例,避免被拖死。我们希望每个业务逻辑服务可以在不借助外部辅助信息(如建设中心节点,由中心节点下发各个业务逻辑服务的健康状态)的情况下,能自行决策迅速屏蔽掉有问题的服务实例,自动把业务流量分散切到其他服务实例上。另外,我们还建设了一套手工操作的全局屏蔽系统,可以在大型网络故障时,由人工介入屏蔽掉某个园区所有的机器,迅速将业务流量分散到其他两个数据园区。
4) 容灾效果检验
三园区容灾是否能正常发挥作用还需要进行实际的检验,我们在上海数据中心和海外的香港数据中心完成三园区建设后,进行了数次实战演习,屏蔽单一园区上千台服务,检验容灾效果是否符合预期。特别地,为了避免随着时间的推移某个核心服务模块因为某次更新就不再支持三园区容灾了,我们还搭建了一套容灾拨测系统,每天对所有服务模块选取某个园区的服务主动屏蔽掉,自动检查服务整体失败量是否发生变化,实现对三园区容灾效果的持续检验。
之前我们在业务迅速发展之时,优先支撑业务功能快速迭代,性能问题无暇兼顾,比较粗放的贯彻了“先扛住再优化”的海量之道。2014年开始大幅缩减运营成本,性能优化就被提上了日程。
我们基本上对大部分服务模块的设计和实现都进行了重新review,并进行了有针对性的优化,这还是可以节约出不少机器资源的。但更有效的优化措施是对基础设施的优化,具体的说是对Svrkit框架的优化。Svrkit框架被广泛应用到几乎所有服务模块,如果框架层面能把机器资源使用到极致,那肯定是事半功倍的。
结果还真的可以,我们在基础设施里加入了对协程的支持,重点是这个协程组件可以不破坏原来的业务逻辑代码结构,让我们原有代码中使用同步RPC调用的代码不做任何修改,就可以直接通过协程异步化。Svrkit框架直接集成了这个协程组件,然后美好的事情发生了,原来单实例最多提供上百并发请求处理能力的服务,在重编上线后,转眼间就能提供上千并发请求处理能力。Svrkit框架的底层实现在这一时期也做了全新的实现,服务的处理能力大幅提高。
我们一直以来都不太担心某个服务实例出现故障,导致这个实例完全无法提供服务的问题,这个在后台服务的容灾体系里可以被处理得很好。最担心的是雪崩:某个服务因为某些原因出现过载,导致请求处理时间被大大拉长。于是服务吞吐量下降,大量请求积压在服务的请求队列太长时间了,导致访问这个服务的上游服务出现超时。更倒霉的是上游服务还经常会重试,然后这个过载的服务仅有的一点处理能力都在做无用功(即处理完毕返回结果时,调用端都已超时放弃),终于这个过载的服务彻底雪崩了。最糟糕的情况是上游服务每个请求都耗时那么久,雪崩顺着RPC调用链一级级往上传播,最终单个服务模块的过载会引发大批服务模块的雪崩。
我们在一番勒紧裤腰带节省机器资源、消灭低负载机器后,所有机器的负载都上来了,服务过载变得经常发生了。解决这一问题的有力武器是Svrkit框架里的具有QoS保障的FastReject机制,可以快速拒绝掉超过服务自身处理能力的请求,即使在过载时,也能稳定地提供有效输出。
近年,互联网安全事件时有发生,各种拖库层出不穷。为保护用户的隐私数据,我们建设了一套数据保护系统——全程票据系统。其核心方案是,用户登录后,后台会下发一个票据给客户端,客户端每次请求带上票据,请求在后台服务的整个处理链条中,所有对核心数据服务的访问,都会被校验票据是否合法,非法请求会被拒绝,从而保障用户隐私数据只能用户通过自己的客户端发起操作来访问。
微信后台有成千的服务模块,部署在全球数以万计的服务器上,一直依靠人工管理。此外,微信后台主要是提供实时在线服务,每天的服务器资源占用在业务高峰和低谷时相差很大,在业务低谷时计算资源被白白浪费;另一方面,很多离线的大数据计算却受制于计算资源不足,难以高效完成。
我们正在实验和部署的资源调度系统(Yard)可以把机器资源的分配和服务的部署自动化、把离线任务的调度自动化,实现了资源的优化配置,在业务对服务资源的需求有变化时,能更及时、更弹性地自动实现服务的重新配置与部署。
基于Quorum算法的KVSvr已经实现了强一致性、高可用且高性能的Key-Value/Key-Table存储。最近,微信后台又诞生了基于Paxos算法的另一套存储系统,首先落地的是PhxSQL,一个支持完整MySQL功能,又同时具备强一致性、高可用和高性能的SQL存储。
链接:http://www.infoq.com/cn/articles/the-road-of-the-growth-weixin-background
// hello.c
#include <stdio.h>
int main()
{
printf(“hello\n”);
return 0;
}
// Android.mk
LOCAL_PATH:= $(call my-dir)
include $(CLEAR_VARS)
LOCAL_SRC_FILES:= hello.c
LOCAL_MODULE:= hello
LOCAL_FORCE_STATIC_EXECUTABLE := true
#LOCAL_STATIC_LIBRARIES := libc
#LOCAL_CFLAGS += -Iinclude/dir -DSOMEFLAGS
include $(BUILD_EXECUTABLE)
在Linode的VPS上配置了VPN服务器(pptpd),连接正常。在我自己的Mac电脑上连接以后无法访问Google或其他国外网站,可正常访问百度和微博等国内网站,QQ也同样可以登录。
通过ip138查询当前访问ip来自VPN服务器所在地,证明我本地是通过VPN服务器访问的其他网站或服务。
同时,我在手机上也使用相同的账户连接同一个VPN服务器,手机可以正常访问Google和其他国外网站,比如twitter。
检查Mac路由表(连接VPN后):
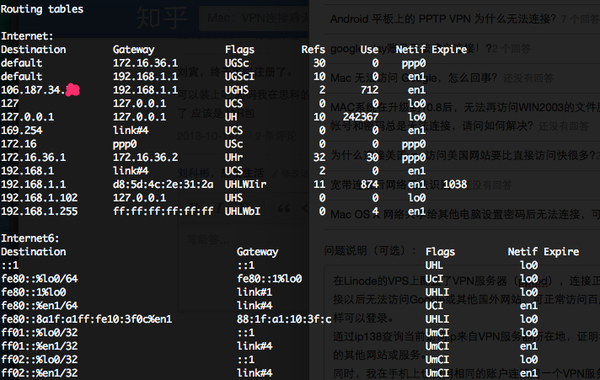
连接VPN后,ping http://google.com 正常,nslookup 也正常,不知道改怎么调试了,求解.
MTU,英文全称为Maximum Transmission Unit,中文即最大传输单元的意思,是一种通信协议层上所能通过的最大数据包值。如果MTU设置得当,可以优化网络性能。反之设置不当,则可能影响网络速度、甚至影响部分软件和网络使用。比如连接上VPN不能访问网站,或不能连接等问题。
由于VPN连接需要对原有的IP或者是TCP/UDP数据进行封装,因此增加了数据的长度。如果VPN连接上不能上网,可以将MTU设置小一些,比如1450,具体设置方法可以参考下文介绍。
除了MTU的设置可能影响VPN连接使用外,如果设置不合理,也可能影响网络连接质量。现在常用的以太网网络下,MTU值默认是1500,超过此大小的话,数据包将被分段传输。如果MTU过小的话,会增加数据包拆分传输次数,而且拆包组包的过程也浪费了时间。
那么按上所说,是不是设置最大值最好呢?答案是否定的,因为在不同使用网络环境,网络MTU最大值也可能不一样。比如ADSL网络MTU值是1492字节,如果强行设置为1500,因为网络本身最大只能1492,超过的话,传输前就需要拆包分段传输,在这过程中也浪费了时间,并且产生额外的数据包。
所以MTU设置需要恰当,不能过大也不能过小,根据网络本身最大MTU传输字节设置即可。那么如何查看使用网络的最大MTU值呢,下面将介绍一下检查方法(Windows下手动查询,如果觉得麻烦,也可以使用Simple MTU Test这个软件查询)。
一、网络最大MTU值检测方法
1、首先同时按下键盘上的Win+R键,弹出“运行”窗口,输入”cmd.exe”,点击确定。
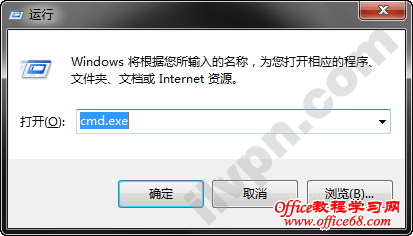
2、在命令行窗口中输入”ping -l 1472 -f www.baidu.com”然后按下回车键。解释一下这段命令的作用:
ping:发送一个数据包检测;
-l(L的小写):指定数据包大小;
1472:数据包大小为1472字节;
-f:禁止路由器拆分数据包;
www.baidu.com:使用百度为检测目标;
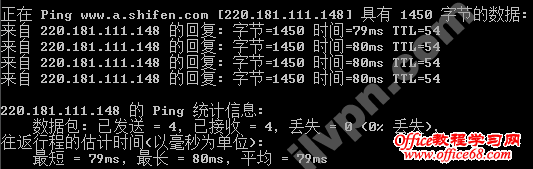
3、执行以上命令后,如果成功响应了(如下图),则说明你的网络MTU最大为1500字节,这时设置MTU为1500即可。(这里我修改了检测数据包为1450,方便截图)
4、如果返回显示需要拆分数据包但是设置 DF。或是Packer needs to be fragmented but DF set.的提示,则说明数据包大小超过了本身网络最大MTU值。

5、这时可以减小发送数据包大小再尝试,依次减少5字节,直到能正确返回响应。返回后逐渐加1字节再次检测,以查询网络最大MTU值。比如查询网络最大MTU值为1452,那么这个并不是完整的MTU值,还需要加上28字节的数据包报文(包含IP头部,但不包含协议栈更下层的头部),完整的MTU应该是1480字节。
6、查询到网络最大MTU值后,设置即可。路由器设置的话,不同路由器,设置方法也可能不一样,建议查看使用说明设置。TP-LINK路由器的话,一般是在管理页面——网络参数——WAN口设置——编辑正在使用的网络连接——WAN口高级设置里。
7、当然除了直接在路由器设置外,还可以在操作系统里修改,下面将介绍一下各系统设置方法。
二、Windows系统设置MTU方法
除了下面介绍的手动设置方法外,一些软件也有辅助修改功能,比如魔方优化大师等。
A、Vista、Win7、Win8系统设置方法
1、打开系统盘\Windows\System32\文件夹下找到cmd.exe,右键“以管理员身份运行”;
2、在“命令提示符”窗口中输入“netsh interface ipv4 show subinterfaces”并回车查看当前的MTU值;
3、接下来输入“netsh interface ipv4 set subinterface “修改的网络连接名” mtu=查询的网络最大MTU值 store=persistent”并回车即可;
例如:“netsh interface ipv4 set subinterface “本地连接” mtu=1492 store=persistent”。
B、Windows XP系统设置方法
1、 按下Win+R组合键,弹出“运行”窗口,输入regedit,点击确定;
2、依次找到以下注册表项:“HKEY_Local_Machine——SYSTEM——CurrentControlSet——Services——Tcpip——Parameters——interface”;
3、在interface中下可能有很多项,需要逐个观察键值,会有一个项与你的网卡IP一致,选中该项;
4、然后在该项上点击右键,选择“编辑——新建——DWORD值”,然后在右侧将其命名为“MTU”;
5、右键点击MTU,选择“修改”,在弹出的窗口中选择“十进制”,设置你查询网络MTU值即可。
6、设置后,需要重启电脑应用生效。
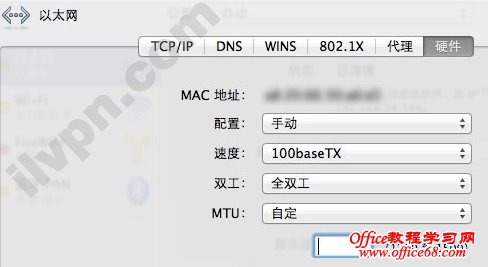
三、Mac OS X设置MTU方法
依次打开:系统偏好设置——网络——以太网(如果使用的是无线网络就修改无线网络)——高级设置,在“硬件”选项卡下“配置”选择手动,然后就可以设置MTU了,如下图:
修改主机名称:
sudo scutil –set HostName 新的主机名
修改共享名称:
sudo scutil –set ComputerName 新的共享名
其实制作 OS X Yosemite 正式版 USB 启动盘的方法有很多,譬如使用命令行的,也有使用第三方工具的。这个教程主要介绍前者,因为这是目前我了解到的最稳妥、简单,而且没有兼容性问题的方法了。

不过大家可别被「命令行」三个字吓到,其实你只需按步骤来,复制粘贴命令即可快速完成,事实上是很简单的。
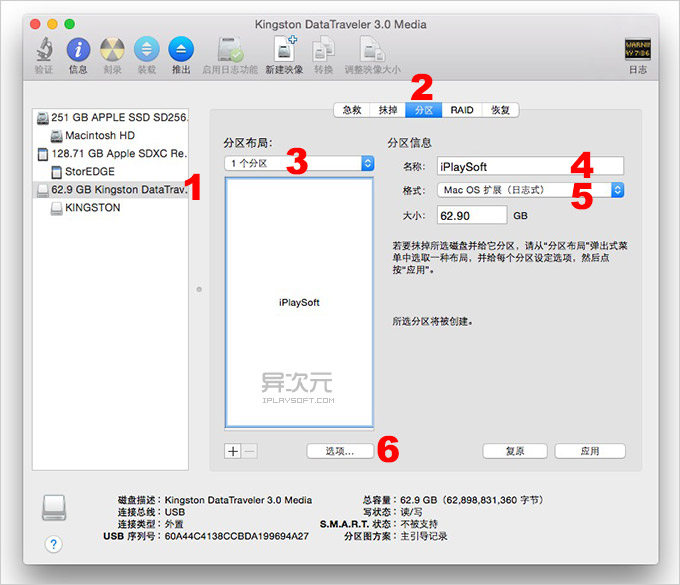
插入你的 U 盘,然后在「应用程序」->「实用工具」里面找到并打开「磁盘工具」,或者直接用 Spotlight 搜索“磁盘工具” 打开,如下图。
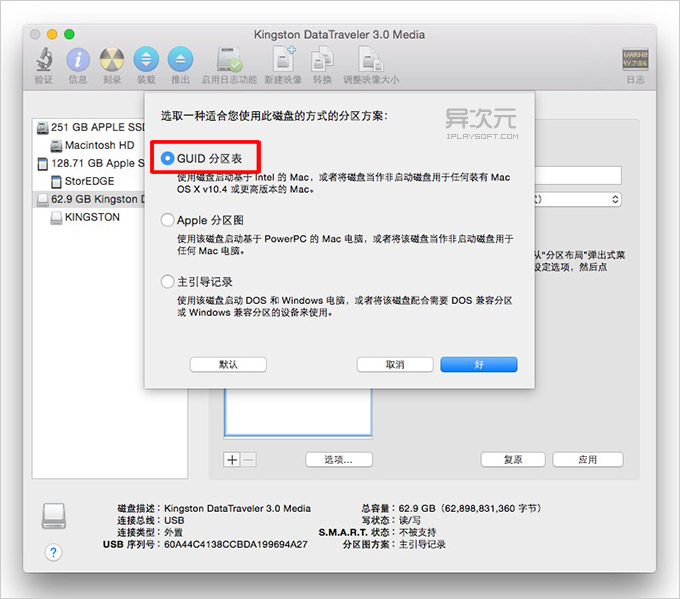
sudo /Applications/Install\ OS\ X\ Yosemite.app/Contents/Resources/createinstallmedia –volume /Volumes/iPlaySoft –applicationpath /Applications/Install\ OS\ X\ Yosemite.app –nointeraction
回车后,系统会提示你输入管理员密码,接下来就是等待系统开始制作启动盘了。这时,命令执行中你会陆续看到类似以下的信息:
Erasing Disk: 0%… 10%… 20%… 30%…100%…
Copying installer files to disk…
Copy complete.
Making disk bootable…
Copying boot files…
Copy complete.
Done.
当你看到最后有 「Copy complete」和「Done」 字样出现就是表示启动盘已经制作完成了!
当你插入制作完成的 OS X Yosemite U盘启动盘之后,桌面出现「Install OS X Yosemite」的盘符那么就表示启动盘是正常的了。那么怎样通过 USB 启动进行全新的系统安装呢?
其实很简单,先在目标电脑上插上 U 盘,然后重启你的 Mac,然后一直按住「option」(alt) 按键不放,直到屏幕显示多出一个 USB 启动盘的选项,如下图。
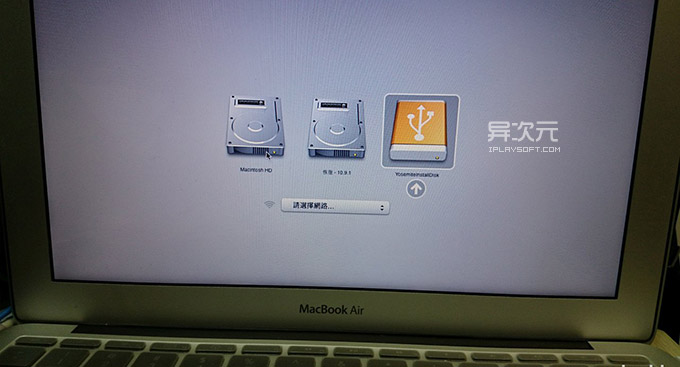
这时选择 U 盘的图标回车,即可通过 U 盘来安装 Yosemite 了!这时,你可以直接覆盖安装系统(升级),也可以在磁盘工具里面格式化抹掉整个硬盘,或者重新分区等实现全新的干净的安装。
link: http://www.iplaysoft.com/osx-yosemite-usb-install-drive.html
Valgrind简介:
Valgrind是动态分析工具的框架。有很多Valgrind工具可以自动的检测许多内存管理和多进程/线程的bugs,在细节上剖析你的程序。你也可以利用Valgrind框架来实现自己的工具。
Valgrind通常包括6个工具:一个内存错误侦测工具,两个线程错误侦测工具,cache和分支预测的分析工具,堆的分析工具。
Valgrind的使用与CPU OS以及编译器和C库都有关系。目前支持下面的平台:
– x86/Linux
– AMD64/Linux
– PPC32/Linux
– PPC64/Linux
– ARM/Linux
– x86/MacOSX
– AMD64/MacOSX
Valgrind是GNU v2下的开源软件,你可以从http://valgrind.org下载最新的源代码。
Valgrind的安装:
1.从http://valgrind.org下载最新的valgrind-3.7.0.tar.bz2d,用tar -xfvalgrind-3.7.0.tar.bz2解压安装包。
2.执行./configure,检查安装要求的配置。
3.执行make。
4.执行make install,最好是用root权限。
5.试着valgrind ls -l来检测是否正常工作。
Valgrind的概述:
Valgrind时建立动态分析工具的框架。它有一系列用于调试分析的工具。Valgrind的架构是组件化的,所以可以方便的添加新的工具而不影响当前的结构。
下面的工具是安装时的标准配置:
Memcheck:用于检测内存错误。它帮助c和c++的程序更正确。
Cachegrind:用于分析cache和分支预测。它帮助程序执行得更快。
Callgrind:用于函数调用的分析。
Helgrind:用于分析多线程。
DRD:也用于分析多线程。与Helgrind类似,但是用不同的分析技术,所以可以检测不同的问题。
Massif:用于分析堆。它帮助程序精简内存的使用。
SGcheck:检测栈和全局数组溢出的实验性工具,它和Memcheck互补使用。
Valgrind的使用:
1.准备好程序:
编译程序时用-g,这样编译后的文件包含调试信息,那Memcheck的分析信息中就包含正确的行号。最好使用-O0的优化等级,使用-O2及以上的优化等级使用时可能会有问题。
2.在Memcheck下运行程序:
如果你的程序执行如下:
myprog arg1 arg2
那么使用如下:
valgrind –leak-check=yes myprog arg1 arg2
Memcheck是默认的工具。–leak-check打开内存泄漏检测的细节。
在上面的命令中运行程序会使得程序运行很慢,而且占用大量的内存。Memcheck会显示内存错误和检测到的内存泄漏。
3.如何查看Memcheck的输出:
这里有一个实例c代码(a.c),有一个内存错误和一个内存泄漏。
#include <stdlib.h>
void f(void)
{
int*x = (int *)malloc(10 * sizeof(int));
x[10]= 0;
//problem 1: heap block overrun
} //problem 2: memory leak — x not freed
int main(void)
{
f();
return0;
}
运行如下:
huerjia@huerjia:~/NFS/valg/test$ valgrind–leak-check=yes ./a
==24780== Memcheck, a memory error detector
==24780== Copyright (C) 2002-2011, and GNUGPL’d, by Julian Seward et al.
==24780== Using Valgrind-3.7.0 and LibVEX;rerun with -h for copyright info
==24780== Command: ./a
==24780==
==24780== Invalid write of size 4
==24780== at 0x80484DF: f() (a.c:5)
==24780== by 0x80484F1: main (a.c:11)
==24780== Address 0x42d3050 is 0 bytes after a block of size 40 alloc’d
==24780== at 0x4026444: malloc (vg_replace_malloc.c:263)
==24780== by 0x80484D5: f() (a.c:4)
==24780== by 0x80484F1: main (a.c:11)
==24780==
==24780==
==24780== HEAP SUMMARY:
==24780== in use at exit: 40 bytes in 1 blocks
==24780== total heap usage: 1 allocs, 0 frees, 40 bytes allocated
==24780==
==24780== 40 bytes in 1 blocks aredefinitely lost in loss record 1 of 1
==24780== at 0x4026444: malloc (vg_replace_malloc.c:263)
==24780== by 0x80484D5: f() (a.c:4)
==24780== by 0x80484F1: main (a.c:11)
==24780==
==24780== LEAK SUMMARY:
==24780== definitely lost: 40 bytes in 1 blocks
==24780== indirectly lost: 0 bytes in 0 blocks
==24780== possibly lost: 0 bytes in 0 blocks
==24780== still reachable: 0 bytes in 0 blocks
==24780== suppressed: 0 bytes in 0 blocks
==24780==
==24780== For counts of detected andsuppressed errors, rerun with: -v
==24780== ERROR SUMMARY: 2 errors from 2contexts (suppressed: 17 from 6)
如何来阅读这个输出结果:
==24780== Memcheck, a memory error detector
==24780== Copyright (C) 2002-2011, and GNUGPL’d, by Julian Seward et al.
==24780== Using Valgrind-3.7.0 and LibVEX;rerun with -h for copyright info
==24780== Command: ./a
这一部分是显示使用的工具以及版本信息。其中24780是Process ID。
==24780== Invalid write of size 4
==24780== at 0x80484DF: f() (a.c:5)
==24780== by 0x80484F1: main (a.c:11)
==24780== Address 0x42d3050 is 0 bytes after a block of size 40 alloc’d
==24780== at 0x4026444: malloc (vg_replace_malloc.c:263)
==24780== by 0x80484D5: f() (a.c:4)
==24780== by 0x80484F1: main (a.c:11)
这部分指出了错误:Invalid write。后面的几行显示了函数堆栈。
==24780== HEAP SUMMARY:
==24780== in use at exit: 40 bytes in 1 blocks
==24780== total heap usage: 1 allocs, 0 frees, 40 bytes allocated
==24780==
==24780== 40 bytes in 1 blocks aredefinitely lost in loss record 1 of 1
==24780== at 0x4026444: malloc (vg_replace_malloc.c:263)
==24780== by 0x80484D5: f() (a.c:4)
==24780== by 0x80484F1: main (a.c:11)
==24780==
==24780== LEAK SUMMARY:
==24780== definitely lost: 40 bytes in 1 blocks
==24780== indirectly lost: 0 bytes in 0 blocks
==24780== possibly lost: 0 bytes in 0 blocks
==24780== still reachable: 0 bytes in 0 blocks
==24780== suppressed: 0 bytes in 0 blocks
这部分是对堆和泄漏的总结,可以看出内存泄漏的错误。
==24780== For counts of detected andsuppressed errors, rerun with: -v
==24780== ERROR SUMMARY: 2 errors from 2contexts (suppressed: 17 from 6)
这部分是堆所有检测到的错误的总结。代码中的两个错误都检测到了。
Helgrind:线程错误检测工具
若使用这个工具,在Valgrind的命令中添加–tool=helgrind。
Helgrind用于c,c++下使用POSIXpthreads的程序的线程同步错误。
Helgrind可以检测下面三类错误:
1.POSIX pthreads API的错误使用
2.由加锁和解锁顺序引起的潜在的死锁
3.数据竞态–在没有锁或者同步机制下访问内存
以数据竞态为例来说明Helgrind的用法:
在不使用合适的锁或者其他同步机制来保证单线程访问时,两个或者多个线程访问同一块内存就可能引发数据竞态。
一个简单的数据竞态的例子:
#include <pthread.h>
int var = 0;
void* child_fn ( void* arg ) {
var++;/* Unprotected relative to parent */ /* this is line 6 */
returnNULL;
}
int main ( void ) {
pthread_tchild;
pthread_create(&child,NULL, child_fn, NULL);
var++;/* Unprotected relative to child */ /* this is line 13 */
pthread_join(child,NULL);
return0;
}
运行如下:
huerjia@huerjia:~/NFS/valg/test$ valgrind–tool=helgrind ./b
==25449== Helgrind, a thread error detector
==25449== Copyright (C) 2007-2011, and GNUGPL’d, by OpenWorks LLP et al.
==25449== Using Valgrind-3.7.0 and LibVEX;rerun with -h for copyright info
==25449== Command: ./b
==25449==
==25449==—Thread-Announcement——————————————
==25449==
==25449== Thread #1 is the program’s rootthread
==25449==
==25449== —Thread-Announcement——————————————
==25449==
==25449== Thread #2 was created
==25449== at 0x4123A38: clone (in /lib/tls/i686/cmov/libc-2.11.1.so)
==25449== by 0x40430EA: pthread_create@@GLIBC_2.1 (in /lib/tls/i686/cmov/libpthread-2.11.1.so)
==25449== by 0x402A9AD: pthread_create_WRK (hg_intercepts.c:255)
==25449== by 0x402AA85: pthread_create@* (hg_intercepts.c:286)
==25449== by 0x80484E1: main (b.c:11)
==25449==
==25449==—————————————————————-
==25449==
==25449== Possible data race during read ofsize 4 at 0x804A020 by thread #1
==25449== Locks held: none
==25449== at 0x80484E2: main (b.c:12)
==25449==
==25449== This conflicts with a previouswrite of size 4 by thread #2
==25449== Locks held: none
==25449== at 0x80484A7: child_fn (b.c:6)
==25449== by 0x402AB04: mythread_wrapper (hg_intercepts.c:219)
==25449== by 0x404296D: start_thread (in /lib/tls/i686/cmov/libpthread-2.11.1.so)
==25449== by 0x4123A4D: clone (in /lib/tls/i686/cmov/libc-2.11.1.so)
==25449==
==25449==—————————————————————-
==25449==
==25449== Possible data race during writeof size 4 at 0x804A020 by thread #1
==25449== Locks held: none
==25449== at 0x80484E2: main (b.c:12)
==25449==
==25449== This conflicts with a previouswrite of size 4 by thread #2
==25449== Locks held: none
==25449== at 0x80484A7: child_fn (b.c:6)
==25449== by 0x402AB04: mythread_wrapper (hg_intercepts.c:219)
==25449== by 0x404296D: start_thread (in /lib/tls/i686/cmov/libpthread-2.11.1.so)
==25449== by 0x4123A4D: clone (in /lib/tls/i686/cmov/libc-2.11.1.so)
==25449==
==25449==
==25449== For counts of detected andsuppressed errors, rerun with: -v
==25449== Use –history-level=approx or=none to gain increased speed, at
==25449== the cost of reduced accuracy ofconflicting-access information
==25449== ERROR SUMMARY: 2 errors from 2contexts (suppressed: 0 from 0)
错误信息从“Possible data race during write of size 4 at 0x804A020 by thread #1
”开始,这条信息你可以看到竞态访问的地址和大小,还有调用的堆栈信息。
第二条调用堆栈从“This conflicts with a previous write of size 4 by thread #2
”开始,这表明这里与第一个调用堆栈有竞态。
一旦你找到两个调用堆栈,如何找到竞态的根源:
首先通过每个调用堆栈检查代码,它们都会显示对同一个位置或者变量的访问。
现在考虑如何改正来使得多线程访问安全:
1.使用锁或者其他的同步机制,保证同一时间只有独立的访问。
2.使用条件变量等方法,确定多次访问的次序。
本文介绍了valgrind的体系结构,并重点介绍了其应用最广泛的工具:memcheck和helgrind。阐述了memcheck和helgrind的基本使用方法。在项目中尽早的发现内存问题和多进程同步问题,能够极大地提高开发效率,valgrind就是能够帮助你实现这一目标的出色工具。
Put the following in a file “patch.m”:
#import <AppKit/AppKit.h>
__attribute((constructor)) void Patch_10_10_2_entry()
{
NSLog(@”10.10.2 patch loaded”);
}
@interface NSTouch ()
– (id)_initWithPreviousTouch:(NSTouch *)touch newPhase:(NSTouchPhase)phase position:(CGPoint)position isResting:(BOOL)isResting force:(double)force;
@end
@implementation NSTouch (Patch_10_10_2)
– (id)_initWithPreviousTouch:(NSTouch *)touch newPhase:(NSTouchPhase)phase position:(CGPoint)position isResting:(BOOL)isResting
{
return [self _initWithPreviousTouch:touch newPhase:phase position:position isResting:isResting force:0];
}
@end
Compile it:
clang -dynamiclib -framework AppKit patch.m -o patch.dylib
Use it:
env DYLD_INSERT_LIBRARIES=/path/to/patch.dylib “/path/to/Google Chrome.app/Contents/MacOS/Google Chrome”
A safer way would be to copy the 10.1.1 AppKit.framework and create as a local framework for just Google Chrome:
cd /Applications/Google Chrome.app/Contents/
mkdir Frameworks
cp -R path-to-10.1.1/AppKit.framework Frameworks/
install_name_tool -change /System/Library/Frameworks/AppKit.framework/Versions/C/AppKit @executable_path/../Frameworks/AppKit.framework/Versions/C/AppKit MacOS/Google Chrome
link: http://www.reddit.com/r/apple/comments/2n721c/temporary_fix_for_chrome_crash_in_yosemite_10102/
Mac下3065破解方法
使用vi打开SublimeText
使用命令:%!xxd 转换 搜索 3342 3442 替换成 3242 3442
:%!xxd -r转回
:wq保存退出
—– BEGIN LICENSE —–
Andrew Weber
Single User License
EA7E-855605
813A03DD 5E4AD9E6 6C0EEB94 BC99798F
942194A6 02396E98 E62C9979 4BB979FE
91424C9D A45400BF F6747D88 2FB88078
90F5CC94 1CDC92DC 8457107A F151657B
1D22E383 A997F016 42397640 33F41CFC
E1D0AE85 A0BBD039 0E9C8D55 E1B89D5D
5CDB7036 E56DE1C0 EFCC0840 650CD3A6
B98FC99C 8FAC73EE D2B95564 DF450523
—— END LICENSE ——